
A friend of mine wondered recently,
What is Python’s default hash algorithm?
I knew that Python objects could implement a __hash__() method, but not what the default hash algorithm was, so I dug into this question a bit.
NOTE: If you’re short on time, the answer is SipHash.
Read on to learn more about what Python uses hashing for and why Python uses the SipHash algorithm specifically.
What is Hashing?
Here’s the Wikipedia definition for a hash function:
A hash function is any function that can be used to map data of arbitrary size to fixed-size values.
You can see how this works by dropping into a Python shell and calling the hash() built-in function on an object:
In [3]: hash("Hash me? No, hash you!")
Out[3]: 2948948632693638043
Notice the length of the string I hashed. Now, I’m going to hash a very short string:
In [11]: hash("hi")
Out[11]: 6035979163977027719
In these examples, the hash() built-in mapped arbitrarily long string objects to fixed-size integers, exactly as Wikipedia’s definition suggested it would.
OK, great, you might think, but what’s the point of hashing?
What Does Python Use Hashing For?
The most important thing that Python uses hashing for is looking up keys in dictionaries, and this is what the Python documentation tells us the hash() builtin is all about:
Hash values […] are used to quickly compare dictionary keys during a dictionary lookup.
A dictionary is a kind of hash table, a data structure that uses a hash function to map keys to values.
As an example of a “lookup,” imagine a dictionary whose keys are the names of people and whose values are phone numbers. The following image shows how a hash function translates the name (the key in the dictionary) to a bucket within the underlying array containing the phone numbers:
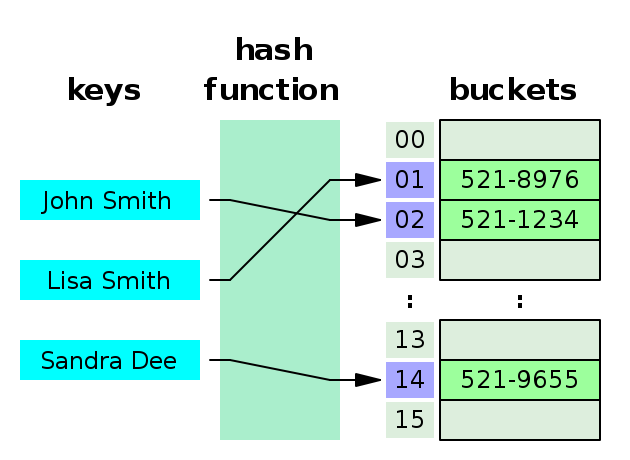
A question about hash tables relevant to this discussion is what happens when two keys have the same hash? If the hash function generates the same hash for two keys, this is called a collision.
Hash tables can handle collisions in different ways. One approach is to use linked lists to track the key-value pairs that share the same hash, like in the following image.

Python dictionaries use a different approach called open addressing. However, regardless of how hash tables manage collisions, there’s a performance cost. This will become important in a moment, when we look at the specific hash algorithm that Python uses.
In summary, we’ve seen that Python uses a hash function to map a key like “Andrew Brookins” to a phone number like “666-666-6666” stored in a dictionary. There are lots of algorithms Python could use to generate these hashes, like CityHash, MurmurHash, DJBX33A, and many more.
So which hashing algorithm does Python use, and more importantly, why does Python use that one?
Why Python Uses SipHash
Python switched to SipHash in version 3.4. Previous to this change, Python used a variant of the Fowler-Noll-Vo hash function.
Why the change? It was all about security. Remember how I said that hash collisions add a performance cost to lookups? Attackers can exploit this to turn, say, an API or HTML form into a denial-of-service attack – if they can manage to create hash collisions.
This is called a collision attack. If an attacker can pull this off, they degrade performance and can potentially take down your web site or API.
Python chose SipHash because it’s a cryptographic hash function with decent performance characteristics, developed by trusted security experts. A “cryptographic” hash function is one that makes finding hash collisions very difficult, and thus prevents attackers from landing collision attacks.
So, there you have it: Python uses SipHash because it’s a trusted, cryptographic hash function that should prevent collision attacks. Until someone figures out how to break it, anyway.
Hash diagrams created by Jorge Stolfi, licensed CC BY-SA 3.0



{kind=link}